

Why (and why not) train a language model from scratch

We work with customers in multiple industries, highly regulated, global and everything in between.
When starting on their AI journeys, many large enterprises consider whether they should build and train a language model from scratch. In this blog, we outline why you would build a language model, what that actually means, when it’s relevant (and not) and summarise our thoughts.
Why build a language model from scratch?
Building a language model from scratch would allow an enterprise to have full control over behaviours and outputs (including reduced reliance on external APIs or third-party models), data privacy (including regulation compliance), domain-specific performance, as well as providing tailored solutions not otherwise possible with off-the-shelf models.
While training a language model from scratch may seem counter-intuitive to many, for some scenarios, it makes perfect sense.
Highly-regulated industries - building a language model from scratch allows for maximum data control and privacy, plus security and auditability, which is essential for highly regulated industries such as financial services.
Customisation and differentiation - for some enterprises, a high level of customisation is required, such as healthcare or life sciences. For some, the value of strategic differentiation is invaluable, for example in investment and trading.
Cost control - your enterprise works at such a scale that costs would rapidly escalate with an out-of-the-box model.
Talent - top talent could be attracted to a number of different scenarios, models and environments, but talent who are looking to build something from scratch that’s completely custom are more likely to join and be retained in this type of business.
What Does Training From Scratch Mean?
Training a language model involves creating the model’s architecture and teaching it to understand language patterns, grammar, and domain-specific knowledge using raw datasets. This process gives organisations unparalleled control over how the model behaves and what it knows. However, this approach is both resource- and time-intensive.
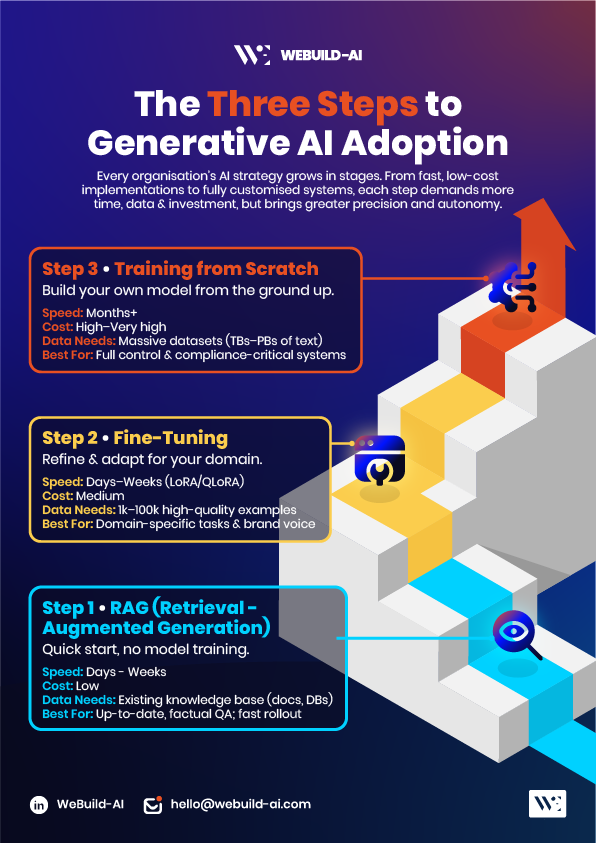
What You Need to Train A Language Model From Scratch?
Data requirements
Data quantity
Training requires tens of terabytes of text data, typically billions of tokens. For example, GPT-3 was trained on 570 GB of filtered text, representing 300 billion tokens, whereas GPT-5 was trained using 16 trillion tokens and 10 trillion parameters. For an enterprise looking to train their own language model, a reasonable ratio to start with would be 100-150GB per 100 billion tokens, also taking into account that the smaller the data set, the cleaner it should be, and considering other factors such as architecture, tokenisation efficiency and data deduplication.
Data quality
Low-quality or biased data can lead to poor generalisation and harmful outputs. Raw data must be carefully curated to remove noise, duplication, and bias. Without curation, a much higher quantity of data would be required, but that would also increase costs, compute and time-to-output significantly.
Domain specific data sets
Domain-specific datasets are often needed to fine-tune the model’s expertise in niche areas. For example, training a model for financial strategy documents would require curated datasets of reports, memos, and regulations.
Hardware
High-performance GPUs or TPUs with distributed training frameworks. Training large models like the GPT family requires clusters of thousands of GPUs.
Budget
Training a GPT-level model can cost $5–$10 million. Even smaller models (e.g., ~1B parameters) cost $50,000–$500,000. Therefore, cost must be considered.
Time
Training can take months, depending on the model size, dataset, and compute power. Therefore, you must consider the time and effort required to train your model based on your business needs.
Skills
As any leader knows, recruiting and retaining the knowledge and expertise in-house is a huge task and requires a robust business, department and team culture, strong leadership, clear communication and peer-to-peer support, as well as more formal structures such as training and opportunities for external learning and development.
When shouldn’t you train a language model from scratch?
Regulation isn’t as strict in your industry - if less security, auditability, data control and privacy is required, standard solutions may allow you to maintain the level of regulation you need.
Customisation and differentiation - if you don’t require much, or any, customisation, a standard solution may also be applicable.
Cost control - training your own language model can cost anywhere between $50,000 and $10M, depending on the customisation, data set size, required security and more. To control costs and forecast more easily, a standard solution may be applicable.
Speed to result - if speed is the most important factor in considering your project, standard out-of-the-box solutions will be ready to use much faster, even though they may not be as flexible or solve every single use case your team requires.
Whether you know your desired outcome or not, WeBuild-AI can support your AI build from discovery to delivery. WeBuild-AI is an AI-native consultancy that delivers new AI-capabilities in a matter of weeks. We are a team of highly-skilled AI experts, based in London, UK.


